Overview
Data is stored in Google BigQuery tables and can be queried via Goliath or Google BigQuery console.
This is good for running queries to get immediate results.
But what if there is a need to run queries daily or at specific times?
What if there is a need to query Google BigQuery data as part of an ETL process?
Magnus features BigQuery Task which provides the ability to query Google BigQuery tables.
As a component of a the workflow, BigQuery Tasks can be scheduled and used along with other tasks to build processes that extract, transform, and deliver data.
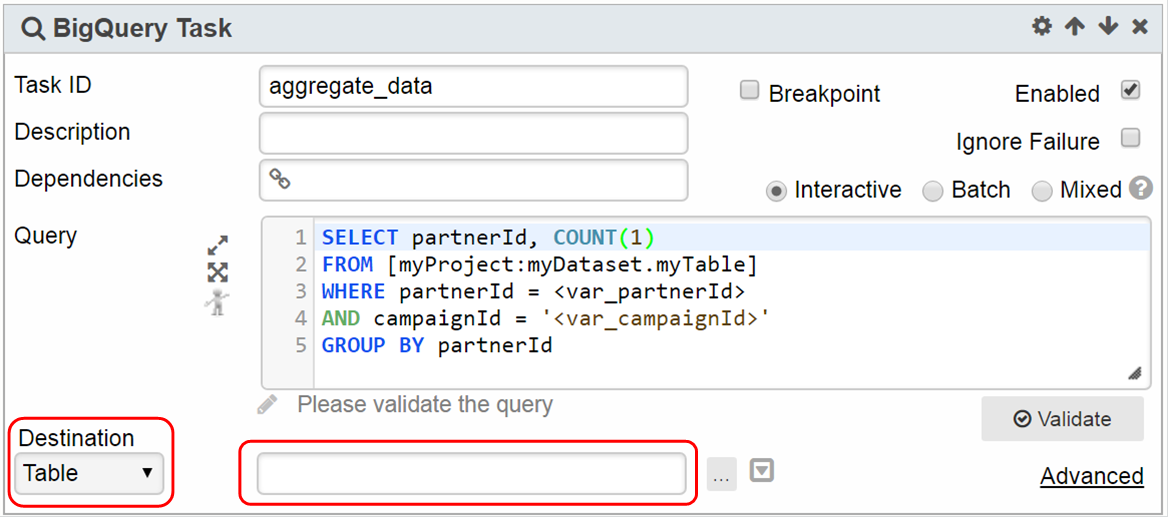
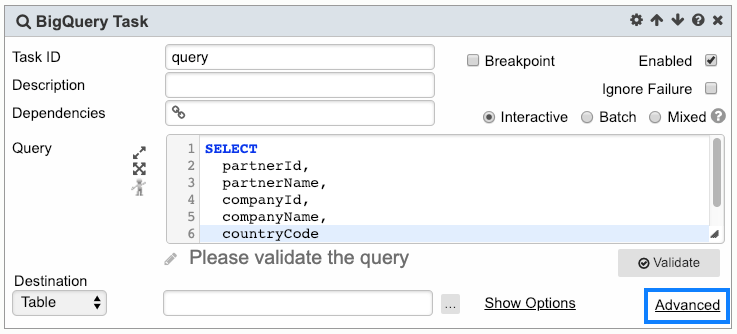
BigQuery Task is the primary task used to query data it provides the ability to save data to table/view/parameter, assign options (billing tier/bytes, table retention, flatten results, and many more), explore query construction in a playground, and incorporate UDF both inline or URI
Front Panel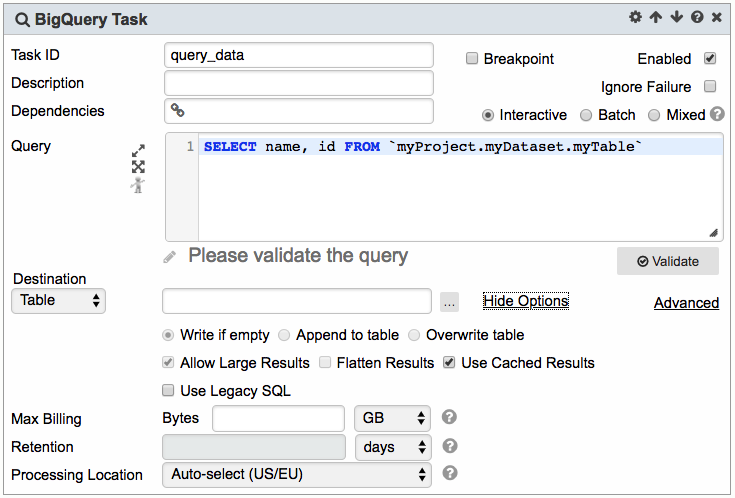
Flip Panel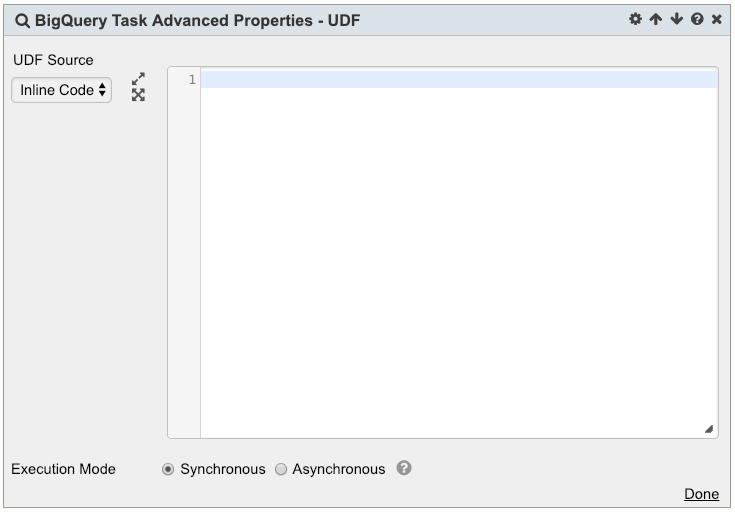
Adding Task
Under Add Task, select the desired position from the "Add to position" drop down list, then click +BigQuery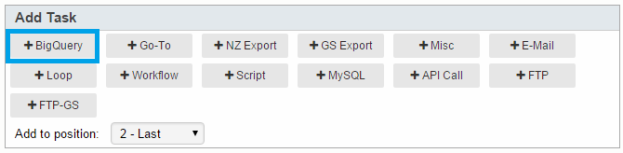
Query
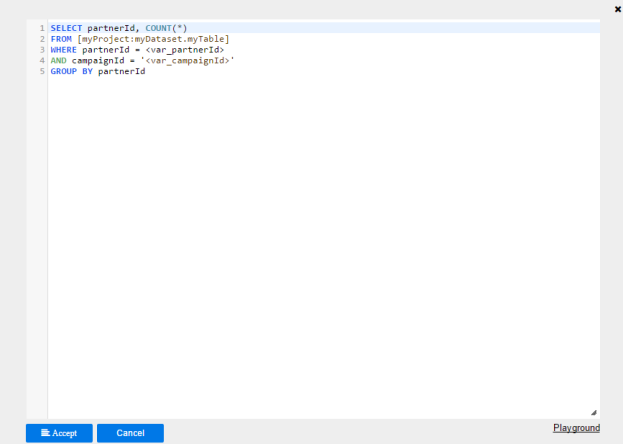
1. Enter the query in the Query textbox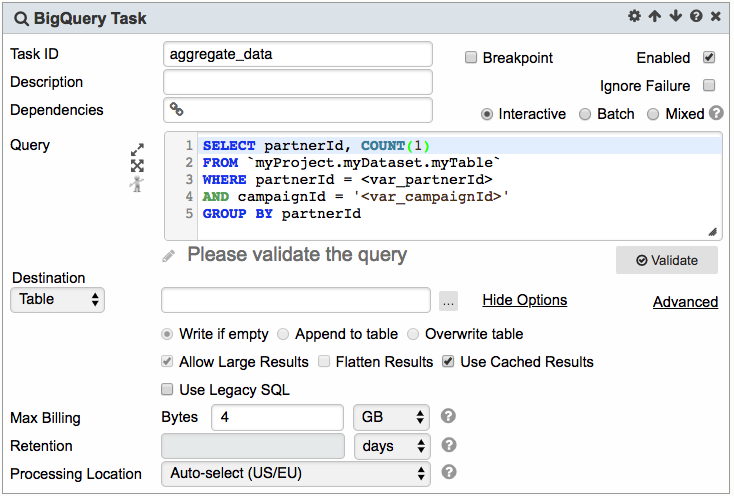
2. The Query textbox is a rich editor. See Rich Editor for more details.
3. Parameters can be used within the query text. For example, the query in the example above is filtered by the parameters var_partnerId and var_campaignId 
Since the parameter var_campaignId is of string type, the filter above can also be written in typed format:AND campaignId = :var_compaignId In this case, the single quotes will be injected automatically at run time.
4. Click on  to open the query in Goliath, parameters used will be carried over also.
to open the query in Goliath, parameters used will be carried over also.
Validation
1. Validation on the query can be done by clicking the validate button 
a. Parameter substitutions are performed on the query using the design time values of the parameters, meaning, the values as you see in the Parameters panel. Note that these values can change during run time depending on the logic of your workflow. For example, you might have a Script task that outputs value to the parameter var_partnerId or var_campaignId.
b. A Google API is called to do a dry-run on the query to validate it. There is no cost involved since it doesn't really run the query. Basic validation is done, for example, it will check for syntax error and it will check if the table exists. Schema against the table is not validated.
c. The Query textbox can be expanded to a popup mode by clicking the icon  .
.
d. The Query textbox can be displayed in full screen mode by clicking the icon  .
.
UDF
1. UDF can be used within the query. To provide sources for the UDFs, click the Advanced link.
Note: this is applicable for BigQuery Legacy SQL. For Standard SQL - UDF is a part of Query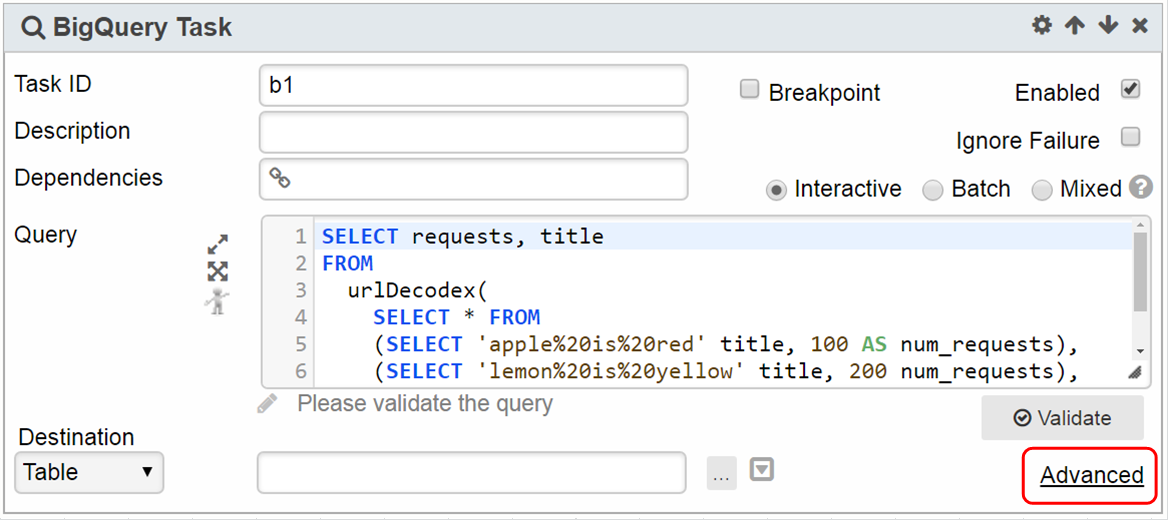
2. There are two options for the UDF source: URIs or Inline Code 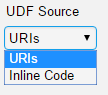
3. Source URIs
a. Path prefixed with gs:// to the UDF source from Google cloud storage must be provided. 
b. Multiple paths delimited with comma can be provided 
c. Parameters can be used to when specifying the Path 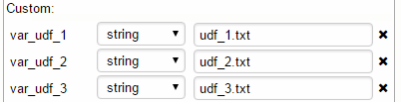

4. Inline Code
a. Provide UDF definition in the textbox 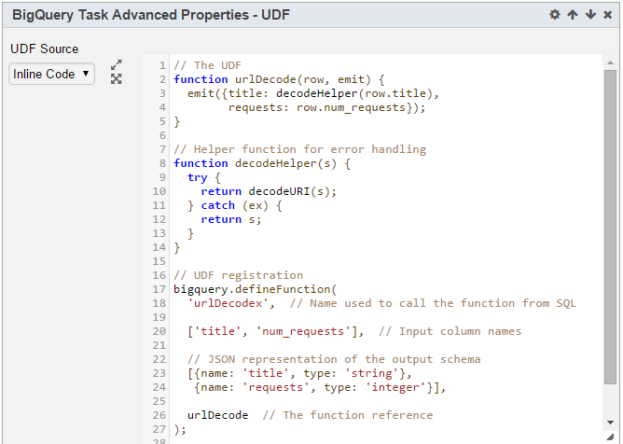
b. Parameters can also be used anywhere in the UDF definition
Destination
There are 3 destination types for the query results:
1. Table
2. Parameter
3. View
Table as Destination
1. Select Table from the Destination drop down list 
2. Then provide the destination table
a. Click the icon  to open the BQ selector to select an existing BigQuery table as the destination
to open the BQ selector to select an existing BigQuery table as the destination 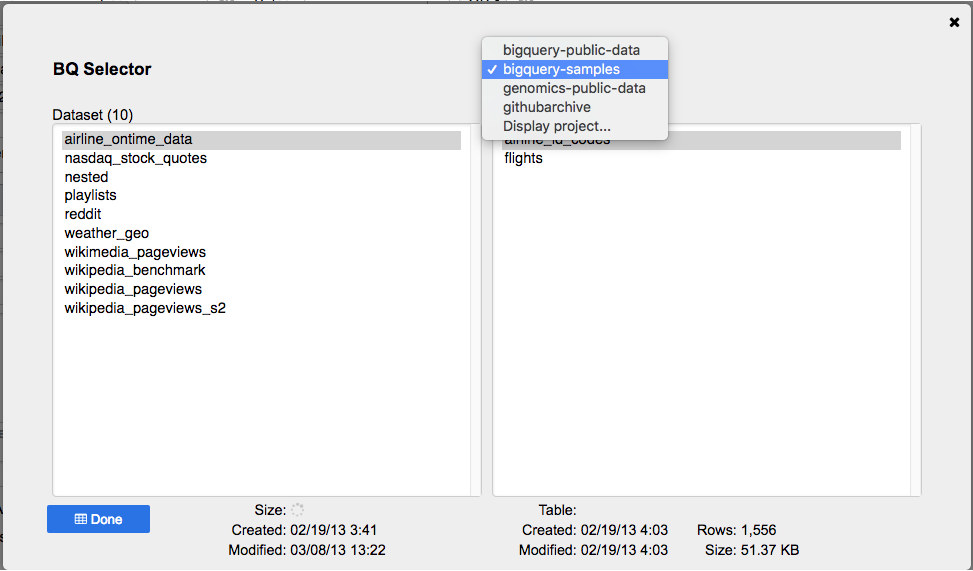
b. The destination table can also be entered manually. It is of the format projectID:datasetID.tableID with optional project ID. If project ID is not provided, for example: myDataset.myResult. User's billing project will be used.
c. Parameters can be used when specifying destination table 
3. Click the icon  to show query options
to show query options 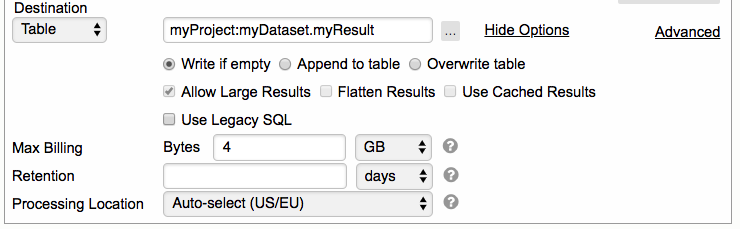
4. By default, the max billing bytes from the user's billing project will be used if no value is specified.
5. By default, the destination table is created without any retention unless retention is set on the dataset level.
a. To set specific retention for the destination table, enter the number of days or hours, parameter can be used here also: 
b. To disable retention for the destination table, set it to 0 days 
c. To leave existing retention as it is for the destination table, leave it empty 
Anonymous Table as Destination
- Select Table from the Destination drop down list
- Leave destination table as empty
- In this case, the destination table will be generated by BigQuery Engine in user's billing project in a temporary dataset and temporary table (so called anonymous table that are hidden from Google BigQuery UI).
The destination table can then be referenced by following tasks in the workflow by this parameter:
<var_taskID_output>
Following the example above, the destination table can be referenced by<var_aggregate_data_output>
![]() Note: using this anonymous table in another query is an unsupported by BigQuery operation , with no guarantees. The query results from this method are saved to a temporary table that is deleted approximately 24 hours after the query is run. The table and dataset name are non-standard, and its use is limited, as the behavior may be unpredictable. Instead, please use explicit destination table described above
Note: using this anonymous table in another query is an unsupported by BigQuery operation , with no guarantees. The query results from this method are saved to a temporary table that is deleted approximately 24 hours after the query is run. The table and dataset name are non-standard, and its use is limited, as the behavior may be unpredictable. Instead, please use explicit destination table described above
5. Click the icon  to show query options
to show query options 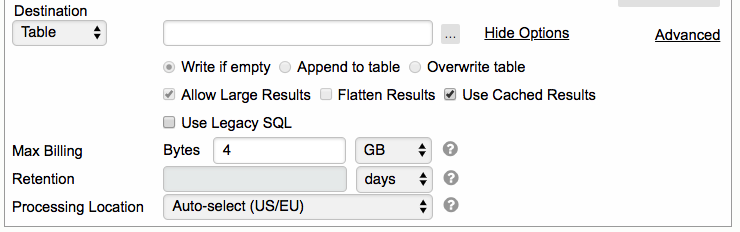
6. "Write if Empty" will always be selected
7. By default, the max billing bytes from the user's billing project will be used if no value is specified.
8. Retention is disabled
Parameter as Destination
When using parameter as the destination, the value to be stored in this parameter cannot exceed 10MB, otherwise you will get “API limit exceeded” error and the Task will fail.
- Select Parameter from the Destination drop down list
- Then select a custom parameter from the drop down list. The selected custom parameter will become workflow-owned.

- If the query is expected to return a record with more than 1 fields, for example:
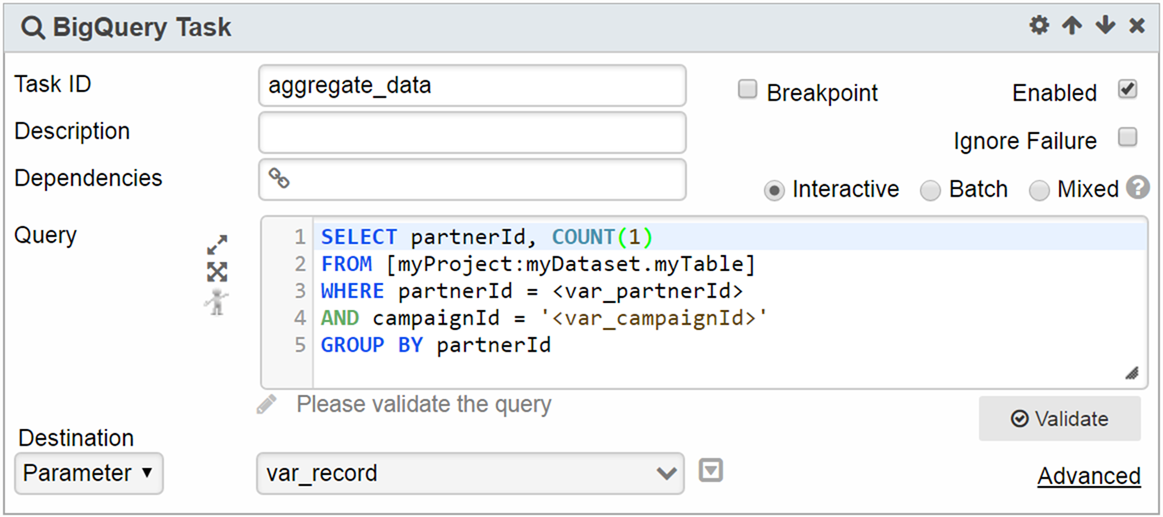
Then a custom parameter of record type can be used. Integer 1-based index or field name can be used to access the fields from the custom parameter:
<var_record[1]> or <var_record[partnerId]>
<var_record[2]> or <var_record[itemCount]> - If the query is expected to return a scalar, then a custom parameter of the correct type: string, number, Boolean can be used.
- Click the icon
 to show query options
to show query options 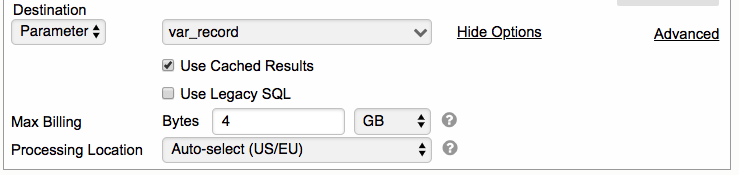
- By default, the max billing bytes from the user's billing project will be used if no value is specified.
- If the query returns more than 1 row, result from the first row will be captured in the specified Parameter.
Moreover, if the query returns 1000 or more rows, the BigQuery Task will fail with this error "Parameter set returned too many records".
View as Destination
- Select View from the Destination drop down list
- Then specify the destination view name

a. Click the icon  to open the BQ selector to select an existing BigQuery view as the destination
to open the BQ selector to select an existing BigQuery view as the destination 
b. The destination view can also be entered manually. It is of the format projectID:datasetID.viewID with optional project ID. If project ID is not provided,
for example:myDataset.myResult
User's billing project will be used.
c. Parameters can be used when specifying view 
3. Click the icon to show query options 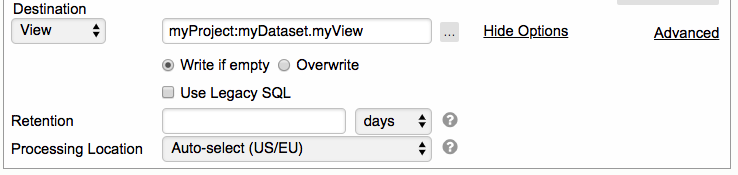
4. By default, the destination view is created without any retention unless retention is set on the dataset level.
a. To set specific retention for the destination view, enter the number of days or hours, parameter can be used here also: 
b. To disable retention for the destination view, set it to 0 days 
c. To leave existing retention as it is for the destination view, leave it empty 
Playground
1. Playground (from popup mode) allows users to visualize and validate with parameter substitutions
2. Click Playground from popup mode to open up playground
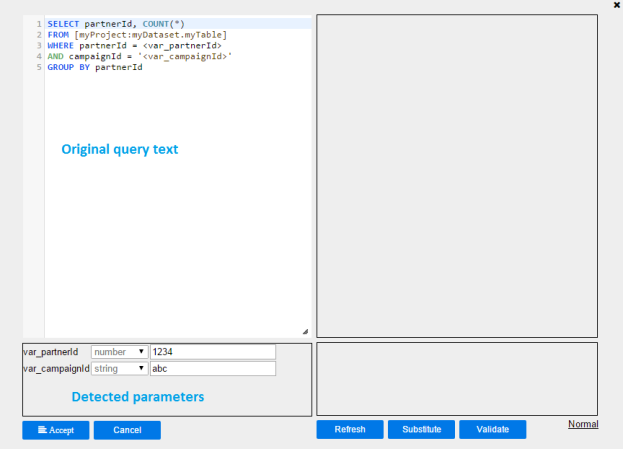
3. The original query text before parameter substitution is displayed in the upper left panel
4. Detected parameters of the format <var_parameter > and :var_parameter from the query text are displayed in the lower left panel 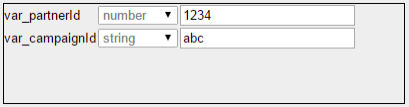
5. Values of the parameters can be adjusted, then click the button  to perform parameter substitutions. Any adjustments to the values of parameters here will not be automatically backfilled into the Parameters panel of the workflow editor. It is the responsibility of the users.
to perform parameter substitutions. Any adjustments to the values of parameters here will not be automatically backfilled into the Parameters panel of the workflow editor. It is the responsibility of the users.
6. The resulting query with highlighted parameter substitutions is displayed on the right upper panel.
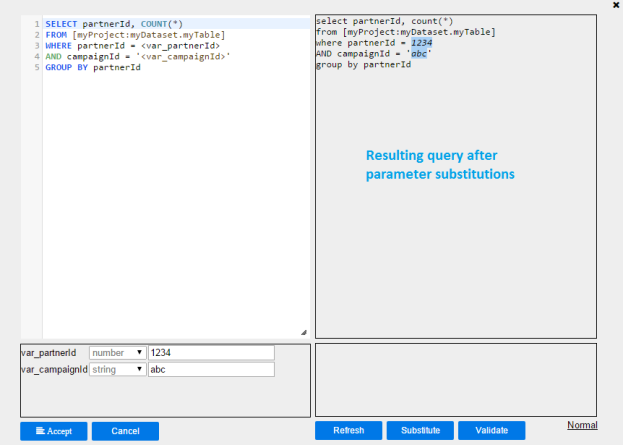
7. Then click  to validate the query. The validation result will be displayed on the lower right panel
to validate the query. The validation result will be displayed on the lower right panel
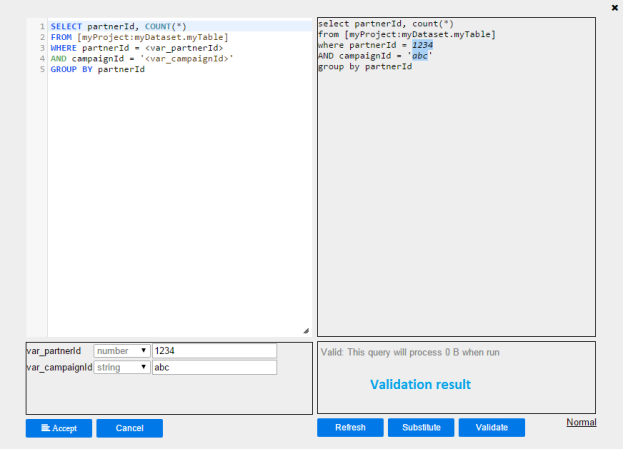
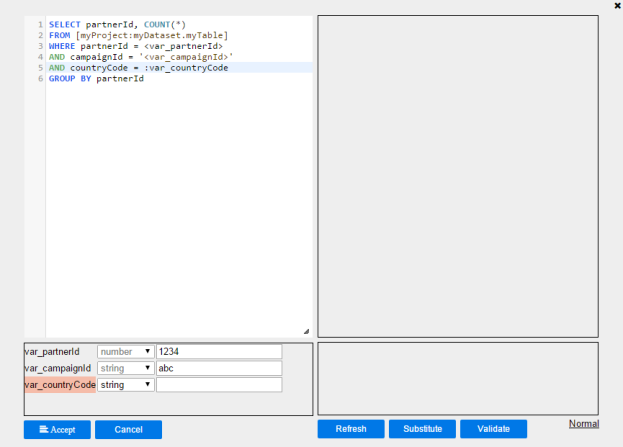
8. The original query text can be modified. After modification, click  . This will perform parameter detection again, and the parameter list will be refreshed to reflect any new parameters detected. Any parameters that are detected but not declared will be highlighted. For example, the parameter var_countryCode is not a built-in/magic/custom parameter, thus it is highlighted:
. This will perform parameter detection again, and the parameter list will be refreshed to reflect any new parameters detected. Any parameters that are detected but not declared will be highlighted. For example, the parameter var_countryCode is not a built-in/magic/custom parameter, thus it is highlighted:
9. In Playground, parameter of typed format only applies for parameter of type string, number, and Boolean. If var_record is a parameter of record type and the field price is of string type, it is users' responsibility to include the single quotes in the query when needed: '<var_record[price]>'
10. When user is done with Playground and satisfy with the query, click  to accept changes made to the query text so that the changes are backfilled in the workflow editor. Or click
to accept changes made to the query text so that the changes are backfilled in the workflow editor. Or click  to discard changes.
to discard changes.
11. Click Normal to return to popup mode
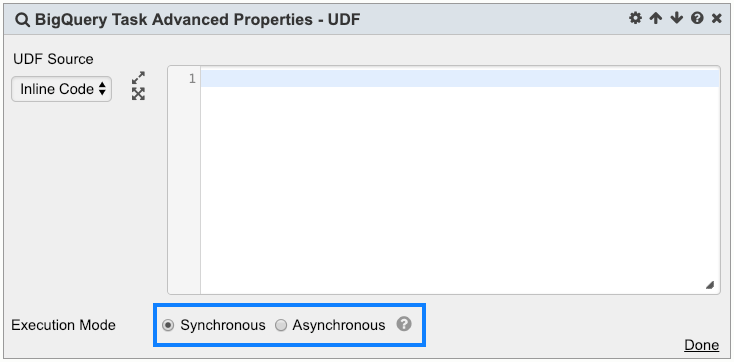
Execution Mode
User can specify to execute the BigQuery Task synchronously or asynchronously. When the BigQuery Task is executed in synchronous mode, the Task will wait for the BQ job to complete before going on to the next Task. When the BigQuery Task is executed in asynchronous mode, the Task will not wait for the BQ job to complete. It will go on to the next Task immediately after the BQ job is submitted. To specify the Execution Mode:
- Click on the Advanced link:
- Specify the Execution Mode:
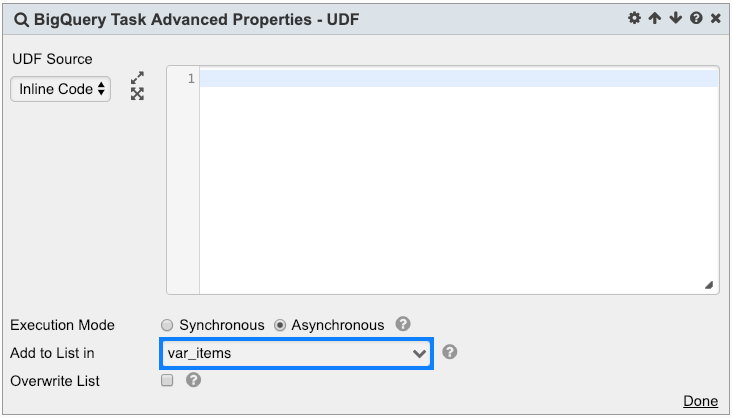
- For asynchronous Execution Mode, user can choose to collect the BQ job in a custom parameter. User can then use Hub Task to wait for the collected BQ Jobs to complete. See Hub Task for more details.
Asynchronous mode is not supported for the following:
- Destination View
- Destination Parameter
- Destination Table with retention specified
- Priority mode Batch
- Priority mode Mixed
- By default, the new BQ job will be appended to the specified parameter. To overwrite the parameter instead, check Overwrite List:
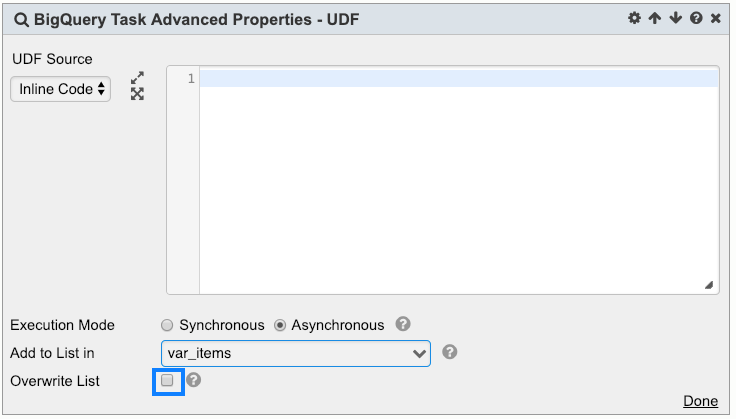
Important:
If user chooses to append to the specified parameter and not overwrite, care must be taken to make sure that the parameter is cleared before first use. Otherwise, since this parameter is Workflow-owned, its state is preserved through Workflow executions. Thus, if user does not clear the parameter before first use, new items will be appended accumulatively to the parameter for each Workflow execution.
Here are some suggestions on how to clear the parameter before first use:- In the Workflow, identify the first BigQuery Task with asynchronous execution mode, and check the checkbox Overwrite List. This ensures that the parameter is cleared and overwritten for the first use. Then for subsequent BigQuery Tasks with asynchronous execution mode, leave the checkbox Overwrite List unchecked, so that new items will be appended to the parameter.
- At the beginning of the Workflow, add a Script Task to clear the parameter. This is a Script Task that returns an empty string and its Return Parameter is set to the parameter to clear.
- At the end of the Workflow, add a Script Task to clear the parameter. This is a Script Task that returns an empty string and its Return Parameter is set to the parameter to clear.
Retry Policy
When Magnus makes a call to Google BigQuery API on behalf of the user to submit the BQ query job (for table or parameter destination) or to create the view (for view destination), Magnus will retry for 10 times with 30 seconds of sleep in between for these HTTP error code:
- 401: Unauthorized error
- 5xx: Google backend error
Magnus does not retry on any other HTTP error code.
Query Priority
BigQuery Task provides 3 options for query priority when destination is Table or Parameter:
- Interactive:
This is a native BigQuery priority.
BigQuery executes interactive queries as soon as possible.
Interactive queries are counted towards concurrent rate limit and daily limit.
More details. - Batch:
This is a native BigQuery priority.
BigQuery executes batch queries as soon as idle resources are available.
This could take minutes or hours.
Eventually BigQuery will change the job priority to interactive if it has not started after 24 hours.
More details.
- Mixed:
This is a custom Magnus priority option.
Magnus submits the query as Interactive and resubmits if the job fails with qualifying BQ error (see below).
Magnus retries 1 time with Interactive priority after which a final retry is submitted with Batch prioriy.
Qualifying BQ error for Mixed Priority
With mixed query priority, if the BQ job fails with rateLimitExceeded error, Magnus will resubmit the job.
RateLimitExceeded error is returned from BigQuery if the billing project exceeds the concurrent rate limit. More details.
Considerations when using Mixed Priority
- Offline token is strongly recommended when the workflow contains BigQuery Task with Mixed Priority. This ensures authorization throughout the query duration.
- Anonymous Table as Destination is not recommended to be used in a workflow if there is any BigQuery Task with Mixed priority since the anonymous table is deleted approximately in 24 hours.
- In the worst case scenario, a BigQuery Task with Mixed priority can take up to 24 hours if the billing project has been swamped with exceed quotas and Batch priority finally kicks in. Extra considerations must be taken for workflows that are scheduled to run once or several times per day.
- Mixed query priority in the context of Execute Workflow Task:
If a child workflow contains a BigQuery Task with mixed priority and the child workflow is not a shared workflow. The child workflow could be locked up to 24 hours in the worst case scenario when Batch Priority kicks in. On the same token, the parent workflow is also locked up to 24 hours
Limitations
- The collected items list cannot exceed 5 million characters in length.
BigQuery Task Retry Example
This example demonstrates how to catch specific error from a BigQuery Task and retry if/when needed.
1. Add a custom parameter called var_maxRetry.
This will determine the maximum number of retries.
For this example, it is set to 50:
2. Add a BigQuery Task named get_iterations.
This sets up the number of retries.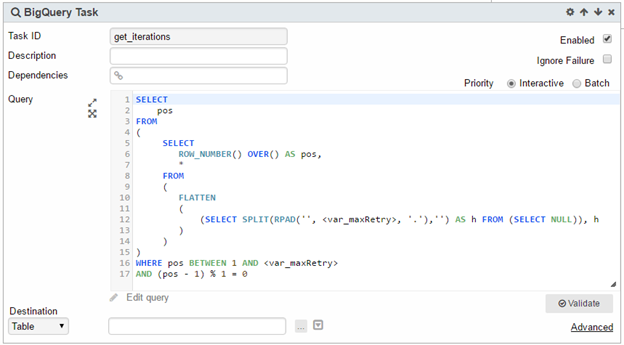
3. Add a Loop Task to do retry: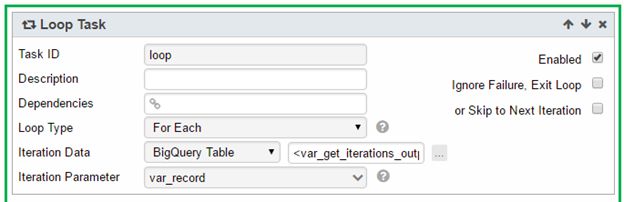
a. The Iteration Data is the BigQuery Table: <var_get_iterations_output>
b. The Iteration Parameter is <var_record>, a custom parameter of Record type.
4. In the Loop Task, add the BigQuery Task that requires retry:
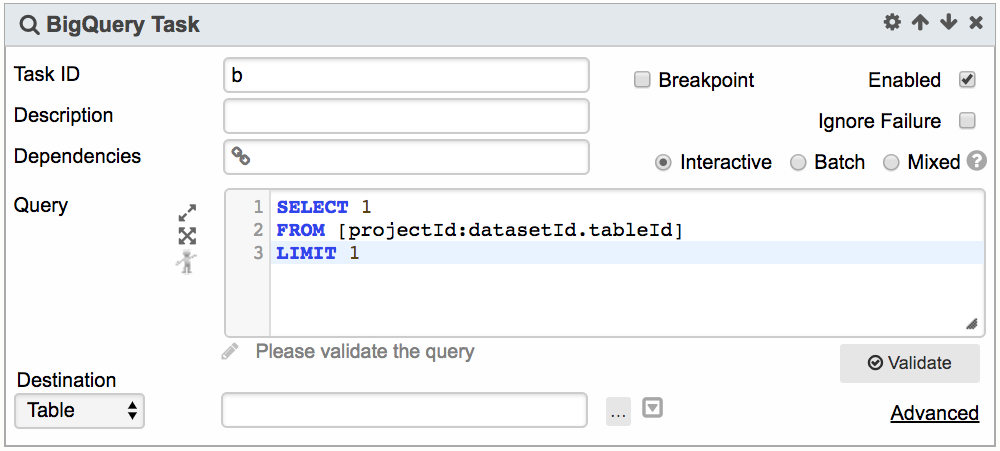
5. In the Loop Task, add a Script Task to captures previous task's error: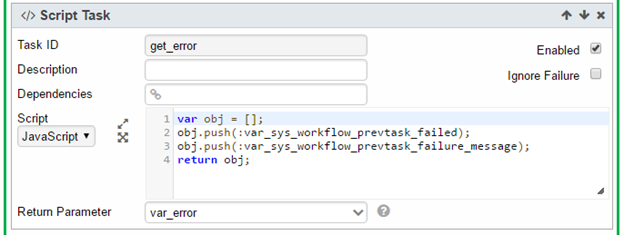
a. The Return Parameter is <var_error> of type Record.
The first field contains value of the magic parameter var_sys_workflow_prevtask_failed.
It has the value true if the previous task fails.
The second field contains the value of the magic parameter ar_sys_workflow_prevtask_failure_message.
It is the error message if the previous task fails.
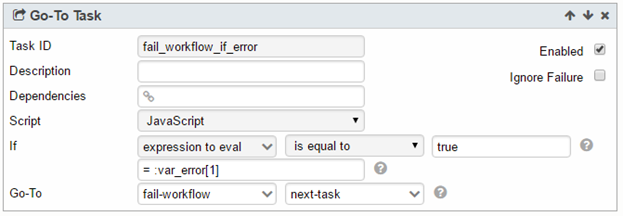
6. In the Loop Task, add a Go-To Task to check for the specific error that qualifies for retry: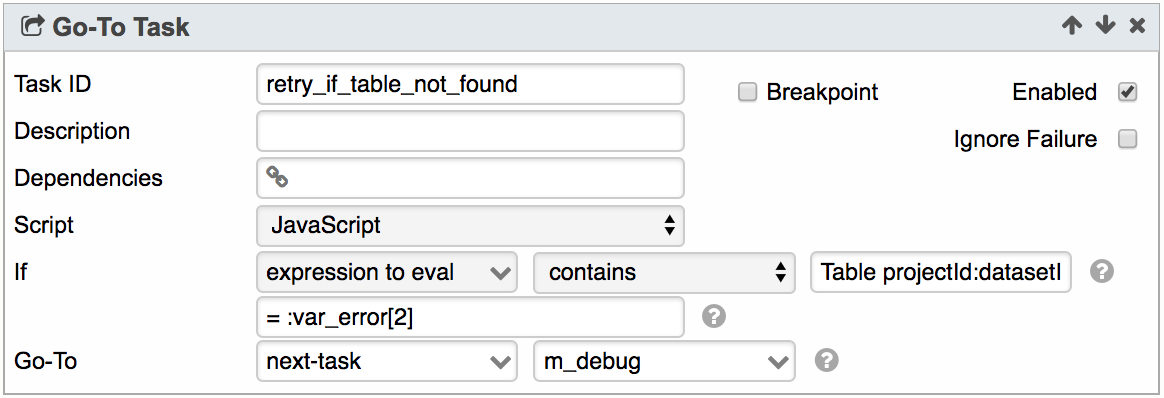
a. For this example, the qualified error for retry is if the BQ table is not found.
So the specified Right Expression is:
Table projectId:datasetId.tableId, reason=notFound
b. If the qualified error is found, the Loop Task will continue.
Otherwise, it will exit the Loop Task by jumping to m_debug, which is a task outside of the Loop Task.
7. In the Loop Task, add a Misc Task to sleep: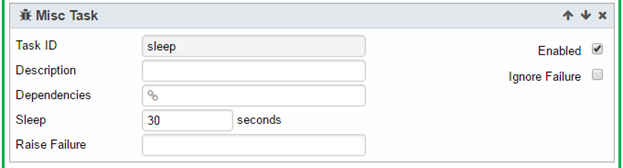
8. So this is the complete Loop Task in collapsed mode):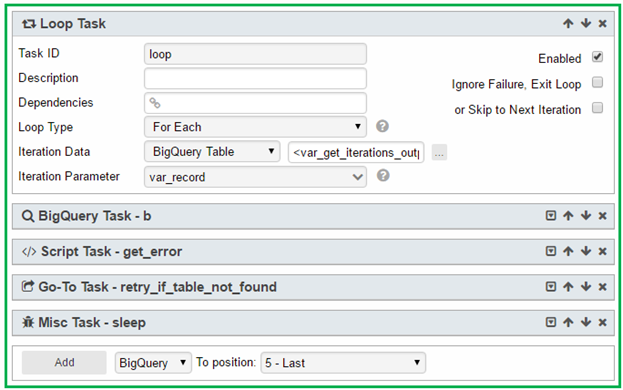
9. Outside of the Loop Task, add a Misc Task for displaying the error for debugging: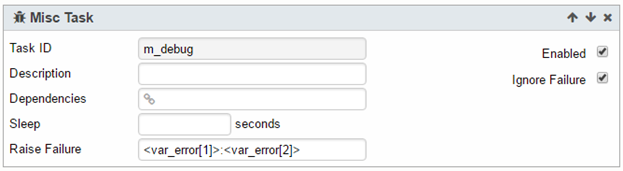
10. Finally, add a Go-To Task to fail the workflow if there is error: